Default Installation (here for extended description and custom installation).
- Extract MyWEST program files from the downloadable MyWEST.zip file. The extraction operation creates working directories and copies inside them the required program files.
- To run MyWEST, a Java 2 Virtual Machine must be installed on the used computer. If it is not installed, download and install a Java 2 Runtime Environment (JRE), version 1.3.1 or above (see here for details).
- To use the database functionalities implemented in MyWEST and store MyWEST extracted data also aggregated in a relational database, a database with a suitable schema must be adequately connected to MyWEST and its correspondent Relational Data Base Management System (RDBMS) (e.g. MS-Access, MySQL, MS-SQL Server, Oracle, Informix, ...) must be installed on the used computer.
Among the RDBMS, the most known and used are MS-Access, which is easily installable on any PC with a MS-Windows operating system, and MySQL that is a well-known open source RDBMS supporting numerous different operating systems including MS-Windows, Linux, and Macintosh, which are the most used by biomedical researchers.
Ready-to-use MS-Access and MySQL databases (i.e. DBgene.mdb and GeneData, respectively) are provided in the MyWEST\data\ subdirectory.
For MS-Access users, the used relational database (e.g. the provided DBgene database) must be registered with the name DBgene in the local ODBC data source.
Start MyWEST
-
For MS-Windows users: run the file MyWEST.bat in the MyWEST main directory. If MyWEST does not start, see here for troubleshooting.
For other platform users (e.g. Macintosh, Unix): from command line simply move to MyWEST main directory and execute "javaw -jar MyWEST.jar".
Example templates.
- To use the provided example templates for extracting annotations from the UniGene, LocusLink, and Swiss-Prot web interfaced databases, go directly to the tutorial extraction section.
Template creation (here for an extended guide; here for a complete troubleshooting)
- Go to MyWEST Template configuration panel (Figure 1).
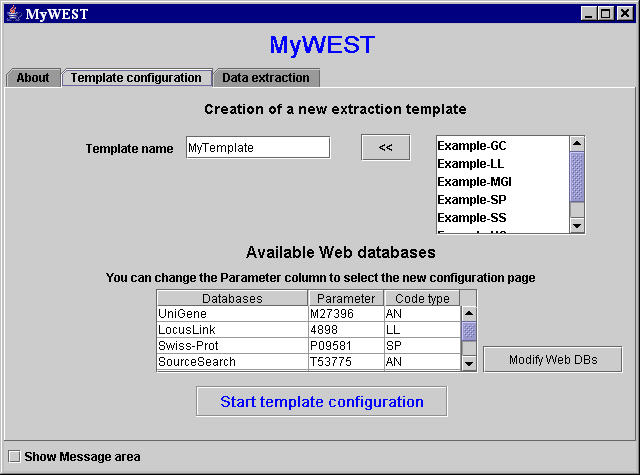
Figure 1. MyWEST template configuration panel
- Provide a name for the template to be created, or choose from the list in the top right part of the panel an existing template to modify [pick it with the mouse and click the << button to select it].
- The table in the center of the panel shows the available web interfaced databases to extract data from.
To change the reference HTML page of a web interfaced database used during template creation, double click on the page clone code in the Parameter column of the table in Template configuration panel (Figure 1) and type the clone ID of the new reference page.
Click the Modify Web DBs button to add web interfaced databases, or to modify accessing parameters of available web interfaced DBs. [See here how.] - Click the Start template configuration button to open the template-building interface (Figure 2) and begin the template configuration.
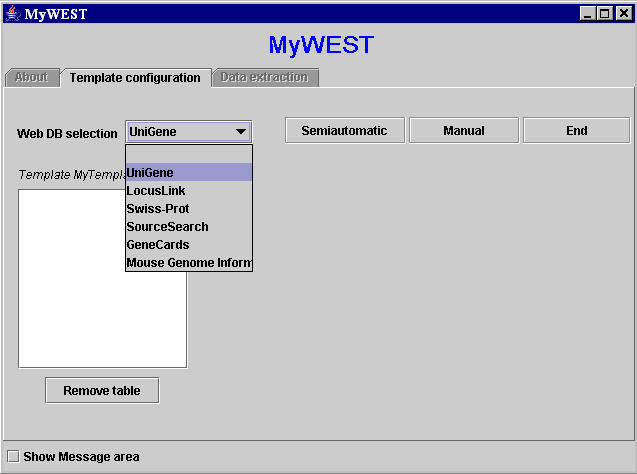
Figure 2. MyWEST template-building interface
- In the Web DB selection menu of the template-building interface (Figure 2), select the web interfaced database to extract the information from. This makes the reference HTML page previously set for the selected web interfaced database appearing in a web browser window. [Troubleshooting I: with some web browsers the user must manually refresh the page visualized in the browser window to see the reference page appearing].
- From the appeared reference HTML page, select few sequences of characters, which can identify the data to extract. This operation varies in relation to the method chosen to create the template. Two template creation modalities have been defined:
- Semiautomatic, for creating templates to extract set of data structured as they appear formatted on an HTML page;
- Manual, for extracting and structuring sparse data on an HTML page.
- Advanced users can click the Change button in the template-building interface (Figure 2) to change the default extraction parameters and customize the extraction performances [see here how].
- In the template-building interface, after selecting in the Web DB selection menu (Figure 2) the web interfaced database to extract the information from (e.g. UniGene) and clicking the Semiautomatic button (Figure 2), for each set of data to extract, select three sequences of characters from the reference HTML page appeared in a web browser window.
- The first sequence of characters, the anchor, must be unique on the page and must be taken within or as closer as possible to the data to extract.
- The other two sequences of characters must be selected within the data to extract.
For example, in order to extract from the UniGene database HTML page in Figure 3 the data inside the dashed line, the sequence of characters "SIMILARITIES", unique in the page, can be provided as anchor. The other two sequences of characters, among the data to extract, can be "H.sapiens" and "asparagine".
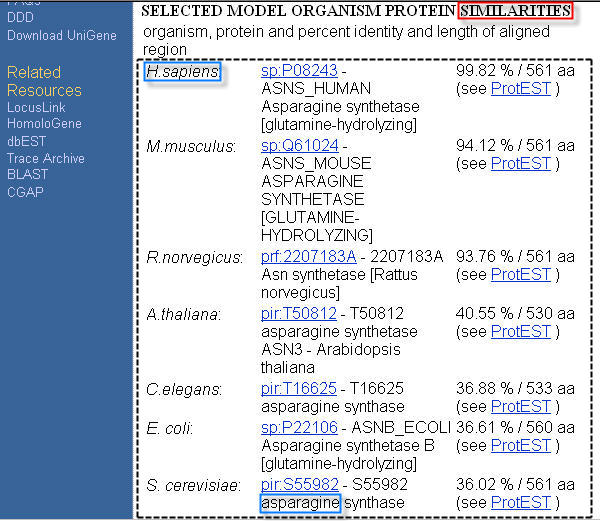
Figure 3. Example UniGene database HTML page
- Copy and paste the three selected sequences of characters in the correspondent text fields in the Semiautomatic selection area (Figure 4) appeared in the template building interface of the MyWEST Template configuration panel after clicking the Semiautomatic button.
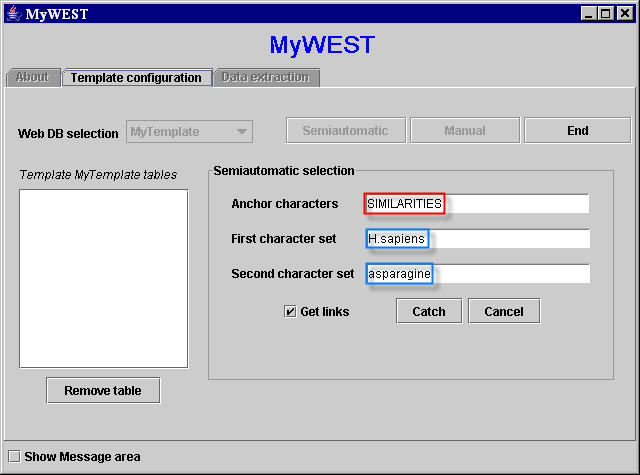
Figure 4. Semiautomatic selection area in MyWEST template building interface
[Troubleshooting III: for a correct functioning, all characters of each of the three selected sequences of characters must have the same appearance and no blank characters (i.e. spaces) must be present at the end of none of the sequences of characters pasted in the text fields of MyWEST template building interface. See more about here]. - Check the checkbox Get links to extract also names and URLs of links in case present in the HTML page within the extracted data.
- Click the Catch button to check for unambiguousness of the three selected sequences of characters in the reference HTML page.
- If not all characters of each of the selected sequences of characters have the same appearance, or blank characters (i.e. spaces) are present at the end of the selected sequences of characters pasted in the text fields of the MyWEST template building interface (Figure 4), a not found warning window appears asking the user to check the selected sequences of characters. [Troubleshooting III].
- If the sequence selected as anchor is not unique on the page, a Select a unique Anchor warning window appears asking the user to provide a new anchor. [Troubleshooting II].
- If the other two selected sequences of characters are not unique, a warning window with the table list of all the sequences of characters in the page equal to the selected sequences appears. The user is asked to unambiguously identify, by selecting the corresponding row in the table list of the warning window (Figure 5), which of the same sequences on the page has actually to be considered. This unambiguous identification is done on the basis of the characters preceding the ambiguous selected sequence on the page (see columns A and B, respectively, of the table list in the warning window (Figure 5)). [Troubleshooting V].
- If the latter unambiguous selected sequences of characters do not belong to the same single HTML structure in the page containing the set of data to extract, or they are not distinct (i.e. they identify a single data), an Extraction problems warning window appears and the user is asked to check and repeat the selection of the sequences of characters. [Troubleshooting IV].
[Note: in case a single data (instead of a set of data) extraction is required, the Manual template creation method must be used].
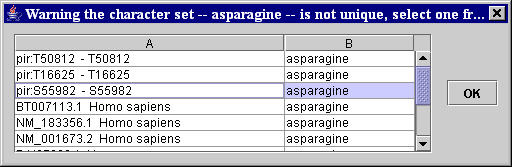
Figure 5. MyWEST warning window for incorrectly selected sequences of characters
- Using the three unambiguous selected sequences of characters MyWEST automatically defines the template, extracts and formats the data identified in the considered reference HTML page and shows them formatted in the extraction result table inside the Extraction results window (Figure 6).
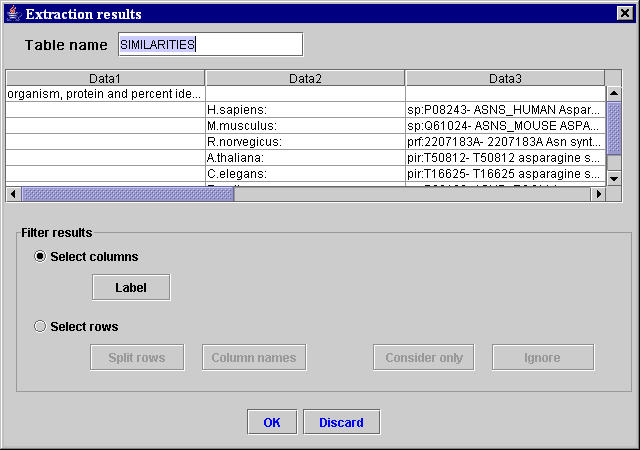
Figure 6. MyWEST extraction results window
- If the extraction is not satisfactory, click the Discard button and repeat the template creation by selecting more adequate sequences of characters or modifying the extraction parameters. [Troubleshooting VI].
- Use the buttons in the Filter results area of the Extraction result window to filter the extracted data according to their values in a "label" column of the extracted result table (Figure 6), or to assign names to the extracted result table columns.
To define a "label" column, select the Select columns radio button, select the table column to set, and click the Label button; the **Label** tag appears in the set label column name.
After setting a label column:- to ignore or to consider only the data in the table rows with specific labels in the label column, select the Select rows radio button, select the only rows to ignore or consider, and click the Ignore or Consider only button, respectively.
- If a table row contains the name of the table columns, select the Select rows radio button, select the row containing the table column names, and click the Column names button to assign as name for each table column the value contained in the correspondent column cell of the selected row.
- If some table rows subdivide logically the extracted data in subtables, select the Select rows radio button, select a subdividing table row, and click the Split rows button to split the extraction result table in subtables divided by the selected split rows. A new result table is created for each splitting row present in the original result table. All the created subtables are shown one at a time in new Extraction results windows (Figure 6), and on each single subtable it is possible to perform all filtering operations.
Starting from the result table in the Extraction results window in Figure 6, to filter out the protein similarities of all organisms but the Homo sapiens, Mus musculus and Rattus norvegicus, perform as follows.- Select the Select columns radio button, clicking on data fields select the table column containing the values to use as label for each row (i.e. in this example Data2) , and click the Label button. The **Label** tag appears beside the selected column name (i.e. Data2**Label**).
- Select the Select rows radio button, select the rows containing “H.sapiens”, “M.musculus”, or “R.norvegicus” in the label column Data2**Label**, and click the Consider only button. Thus, only the Homo sapiens, Mus musculus and Rattus norvegicus protein similarities remain in the result table of the Extraction results windows (Figure 7).
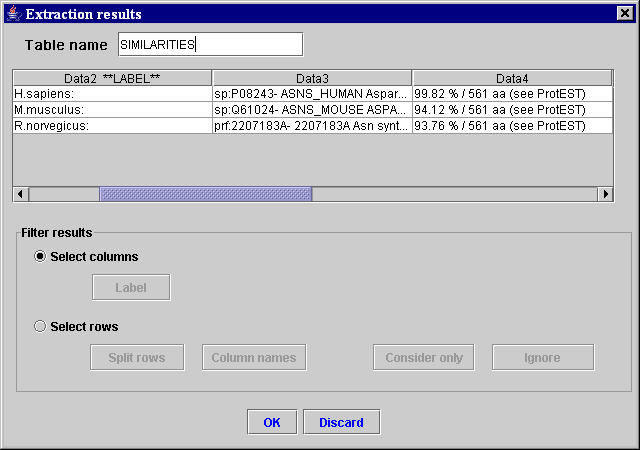
Figure 7. MyWEST extraction results window with filtered data
- Type a name for the extracted and filtered data table in the Table name text field of the Extraction results window (Figure 7) [the default name is the sequence of characters selected as "anchor" for the extracted data].
- If the extraction and filtering is not satisfactory, click the Discard button and repeat the template creation by selecting more adequate sequences of characters or modifying the extraction parameters. [Troubleshooting VI].
- Click the OK button to save the created data extraction and filtering template as a template table.
- The name of the new created template table is shown in the text area on the left side of the main template building interface of MyWEST Template configuration panel (Figure 8). To delete a created template table, select the template table name appeared in this text area and click the Remove table button.
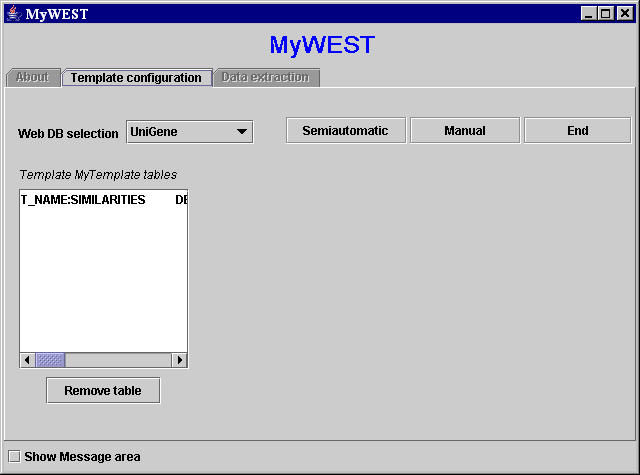
Figure 8. MyWEST template-building interface with the created template table
- Click the End button to finish the template configuration. [Troubleshooting VII].
- Manually created templates are formed of "extraction units", one for each type of data to extract from the HTML page, representing the columns of the extraction result table.
After selecting in the Web DB selection menu of the template-building interface (Figure 9) the web interfaced database to extract the information from (e.g. UniGene), and clicking the Manual button (Figure 9), for each extraction unit select two sequences of characters from the reference HTML page appeared in a web browser window.
- The first sequence of characters, the anchor, must be unique on the page and must be taken as closer as possible to the data to extract.
- The second sequence of characters must be selected within the data to extract.
Figure 9. MyWEST template-building interface
For example, in order to extract from the UniGene databank HTML page in Figure 10 the data inside the two red boxes, two extraction units must be defined. The sequences of characters "Genome View" and "Genetic map", unique in the page, can be provided as anchors for the first and second extraction unit, respectively. The other sequences of characters must be selected among the data to extract (e.g. "7" and "7q21.3 cM").
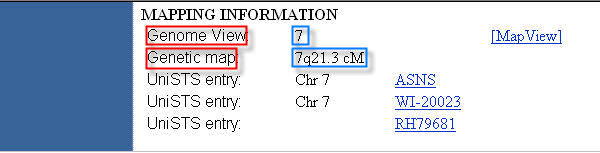
Figure 10. Example UniGene database HTML page
- Copy and paste the two selected sequences of characters in the correspondent text fields in the Manual selection area (Figure 11) appeared in the template building interface of the MyWEST Template configuration panel after clicking the Semiautomatic button.
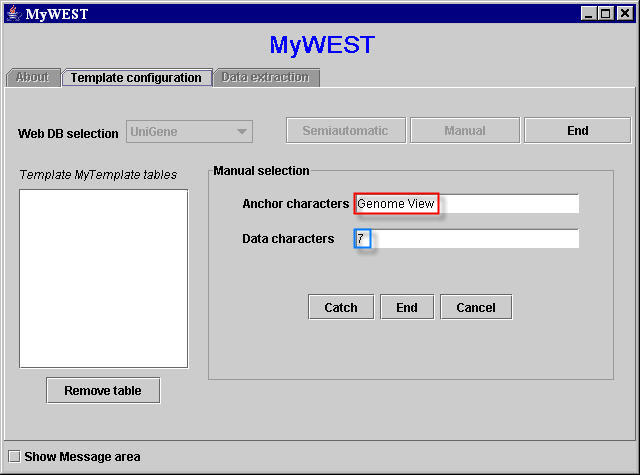
Figure 11. Manual selection area in MyWEST template building interface
[Troubleshooting III: for a correct functioning, all characters of each of the two selected sequences of characters must have the same appearance and no blank characters (i.e. spaces) must be present at the end of none of the sequences of characters pasted in the text fields of MyWEST template building interface. See more about here].
- Click the Catch button to check for unambiguousness of the two selected sequences of characters in the reference HTML page.
- If not all characters of each of the selected sequences of characters have the same appearance, or blank characters (i.e. spaces) are present at the end of the selected sequences of characters pasted in the text fields of the MyWEST template building interface (Figure 11), a not found warning window appears asking the user to check the selected sequences of characters. [Troubleshooting III].
- If the sequence selected as anchor is not unique on the page, a Select a unique Anchor warning window appears. The not unique sequence of characters selected as anchor is considered as “label” for the data to extract, and the user is asked to provide a new anchor and to unambiguously identify, by selecting the correspondent row in the table list of the appeared warning window (Figure 12), which of the first selected anchor same sequences of characters on the page has actually to be considered as “label” for the data to extract. [Troubleshooting II].
- If the other selected sequence of characters is not unique, a warning window with the table list of all the sequences of characters in the page equal to the selected sequence appears. The user is asked to unambiguously identify, by selecting the correspondent row in the table list of the appeared warning window (Figure 12), which of the same sequences on the page has actually to be considered. [Troubleshooting V].
All unambiguous identifications are done on the basis of the characters preceding on the page the ambiguous selected sequence (see columns A and B, respectively, of the table list in the appeared warning window (Figure 12)).
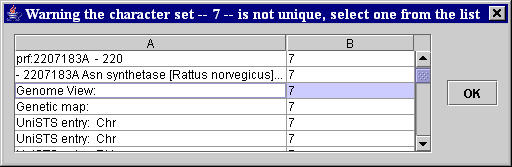
Figure 12. MyWEST warning window for incorrectly selected sequences of characters
- Using the two unambiguous selected sequences of characters MyWEST automatically defines the template, extracts the data identified in the considered reference HTML page for the extraction unit and shows them in a Selection results window (Figure 13).
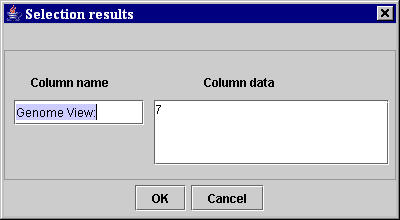
Figure 13. MyWEST selection results window
- Type a name for the extraction unit (a data column of the final extraction result table) in the Column name text field of the Selection results window (Figure 13) [the default name is the sequence of characters selected as "anchor" for the extraction unit].
- If the extraction is not satisfactory, click the Cancel button and repeat the template extraction unit creation by selecting more adequate sequences of characters or modifying the extraction parameters for the entire template. [Troubleshooting VI].
- Click the OK button to finish the extraction unit creation and to go back to the Manual selection area of the template building interface in the MyWEST Template configuration panel (Figure 11) to create a new extraction unit for the building template.
- When all extraction units have been created, click the End button in the Manual selection area of the template building interface in the MyWEST Template configuration panel (Figure 11). All extraction units created are shown formatted in the extraction result table inside the Extraction results window (Figure 14).
[Troubleshooting VII: at this time by clicking instead the End button in the top right part of the template building interface in the MyWEST Template configuration panel (Figure 11), the template creation is ended without saving the creating template.]
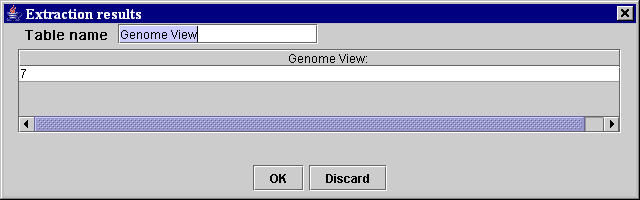
Figure 14. MyWEST selection results window
- If the extraction is not satisfactory, click the Discard button and repeat the creation of all template extraction units by selecting more adequate sequences of characters or modifying the extraction parameters. [Troubleshooting VI].
- Click the OK button to save the created data extraction template as a template table.
- The name of the new created template table is shown in the text area on the left side of the main template building interface of the MyWEST Template configuration panel (Figure 15). To delete a created template table, select the template table name appeared in this text area and click the Remove table button.
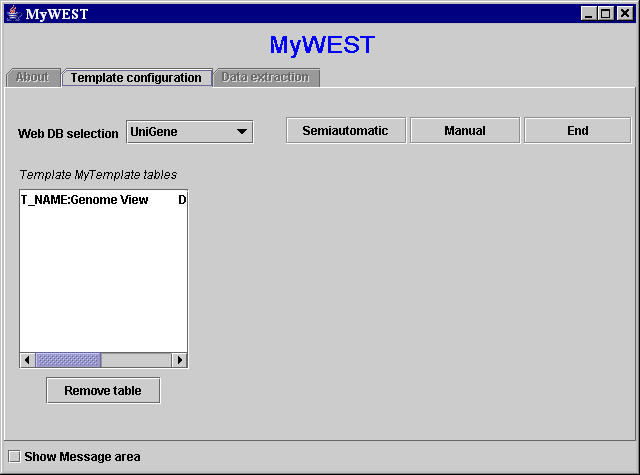
Figure 15. MyWEST template-building interface with the created template table
- Click the End button in the top right part of the panel to finish the template configuration.[Troubleshooting VII].
Extraction from multiple HTML pages (here for an extended guide).
- Go to MyWEST Data extraction panel (Figure 16).
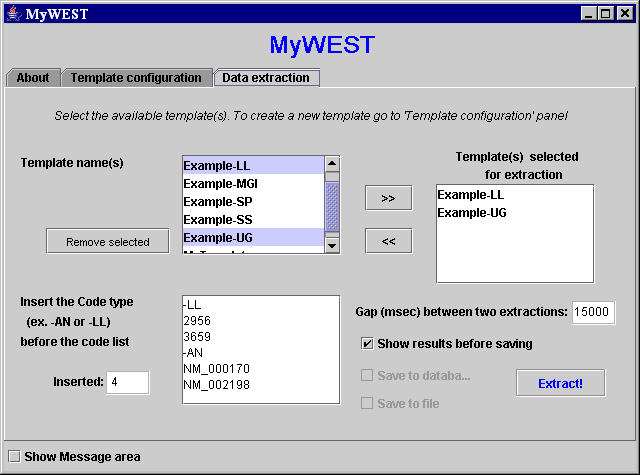
Figure 16. MyWEST data extraction panel
- Select from the Template name(s) list of available templates (Figure 16) the template/s to use for extracting the data [pick it/them with the mouse and click the >> button to select it/them].
The selected templates are listed in the Template(s) selected for extraction text area (Figure 16). To remove template/s from this list, pick it/them with the mouse and click the << button.
[ATTENTION: by clicking the Remove selected button, the template/s selected in the Template name(s) list (Figure 16) are deleted for good!] - Insert in the text area at the bottom of the Data extraction panel (Figure 16) the list of identification codes of the nucleotide and/or aminoacidic sequences whose annotations have to be extracted.
The identification codes must be inserted each in a distinct row and grouped in blocks according to their code type. Each block must be preceded by a row identifying the block code type and containing the same code type label associated in the table within the Template configuration panel (Figure 17) to the databank to extract the data from (e.g. -AN for GenBank Accession Numbers, -LL for LocusLink IDs, -SP for Swiss-Prot Accession Numbers).
The Inserted text field shows the number of sequence identification codes actually inserted in the text area at the bottom of the Data extraction panel (Figure 16).
Figure 17. MyWEST template configuration panel
- Set in the Gap between two extractions (msec) text field (Figure 16) the millisecond gap (default 1000) between the data extractions of two subsequent sequence identification codes in the list at the bottom of the Data extraction panel (Figure 16).
[Note: for long sequence identification code lists, set this value to 15000, at least, to avoid loading a database web server with many concentrated requests and risking the permanent cutting of the connection to that web sever for the used computer IP]. - Uncheck the Show results before saving checkbox to avoid visual inspection of each of the extraction result tables and to directly store the extracted data.
Uncheck the Save to database or the Save to file checkbox to avoid saving the extracted data aggregated into the relational database or in Excel text files, respectively. - Click the Extract! button to start the extraction.
- At the end of the extraction, if the checkbox Show results before
saving was set (Figure 16), an extraction result table (Figure 18) appears for each table defined in the used template/s. Thus, the extracted annotations can be visually evaluated and saved or discarded. It is also possible to manually filter the extraction results by selecting and removing columns and/or rows eventually containing useless data.
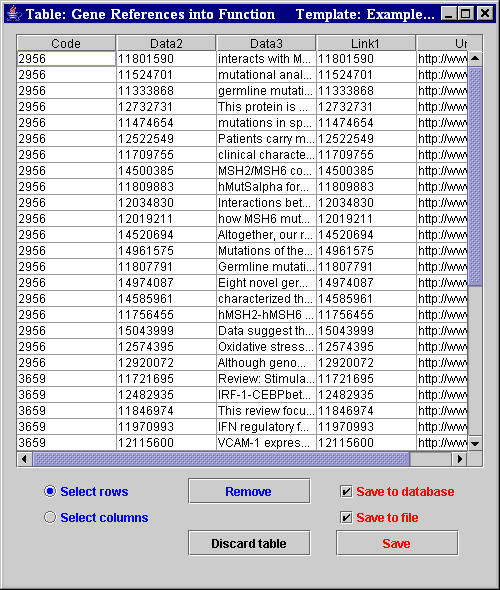 |
Figure 18. MyWEST extraction result table |
Extraction and database configuration (here for an extended guide).
- Many parameters are available in MyWEST to optimize extraction performance, change the database where storing the extracted data, and define new web interfaced databases from which retrieving annotations.
All parameter values can be configured by editing the two text files Config.txt and DatabasesURL.txt. See here for details.
- Check extraction log file (Figure 19) in the MyWEST/logs/ directory to rapidly evaluate extraction results. Here for more details.
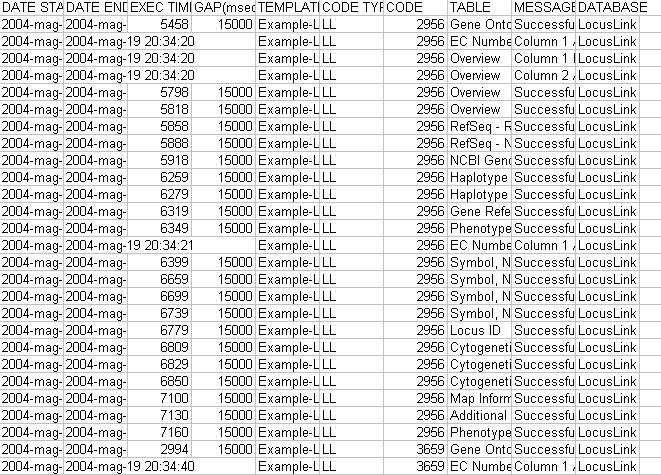 |
Figure 19. Example of MyWEST extraction log file |
Mining data extracted
- To mine the extracted data stored in the relational database, you can write your specific queries in Structured Query Language (SQL), or use the SQL queries we developed for MS-Access and MySQL databases. See here how to perform queries on these databases.
Updating (here for an extended guide).
- Extracted annotations aggregated in the local relational database can be kept updated using the MyWEST update program according to the following instructions.
- In the Templates.txt file inside MyWEST/updating/ directory, type the name/s of the template/s to use for the extraction (here for an example).
- In the Codes.txt file inside MyWEST/updating/ directory, type the list of nucleotide and/or aminoacidic sequence codes to extract annotation for (here for an example).
- By default, the data extractions from two subsequent HTML pages are performed with a 15000 millisecond gap and extracted annotations are saved both in Excel text files and in the local relational database. If you want to change the extraction gap or save the updated annotations in the relational database or in Excel text file only, edit the MyWEST-Up.bat file inside MyWEST/updating directory modifying the "output" parameter value. See here how. [Note: the updating functionality properly works only after MyWEST has been correctly connected to a relational database].
- For MS-Windows users: run the file MyWEST-Up.bat inside MyWEST/updating directory.
For other platform users (e.g. Macintosh, Unix): from command line move to MyWEST main directory and execute "javaw -jar MyWEST-Up.jar updating/Templates.txt updating/Codes.txt gap=15000 output=xls+db". If needed, change the default 15000 millisecond gap between two subsequent HTML page extractions, and/or the output parameter value indicating where to store the updated extractions.